Day4|Java基础数据类型全解析
在编程的世界里,数据是构建一切逻辑的基石。
无论是计算一个简单的数值、存储用户的姓名,还是处理复杂的业务逻辑,我们都需要通过数据类型来定义数据的本质和行为。
作为一门强类型语言,Java对数据类型的严谨设计,既保障了代码的健壮性,也隐藏了很多开发者容易忽视的细节和技巧。
从int到double,从char到boolean,Java的八大基础数据类型看似简单,却直接影响着内存效率、计算精度,甚至是代码的底层性能。
Integer和int有什么区别?有没有在类型转换的时候遇到过精度丢失?为什么0.1 + 0.2在计算机中并不等于0.3?
接下来,我们一起看看Java的每一种基础数据类型,揭开其背后的存储机制、使用场景与潜在陷阱。无论你是 Java新手,还是希望巩固基础的资深开发者。让我们从最基础的“0和1”出发,重新认识这些构建Java世界的原子单元。
一、Java数据类型的分类
Java数据类型分为两大类:
- 基本数据类型:直接存储数据值,内存分配在栈(Stack)中,共 8 种。
- 引用数据类型:存储对象的引用(内存地址),如类、数组、接口等,内存分配在堆(Heap)中。
本文主要聚焦8 种基本数据类型,它们是 Java 程序中最基础的“原子单元”,直接决定数据的存储方式与计算行为。
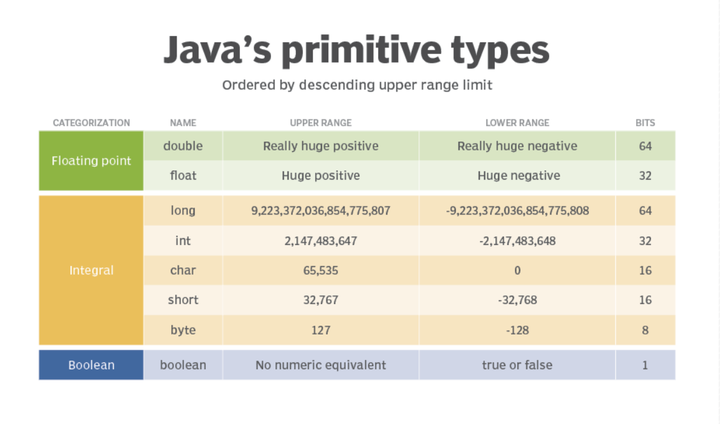
二、Java中有哪些基础数据类型?
下面我们带着各种疑问和小练习一起学习下
2.1 整型
Java 整型其取值范围与内存占用严格遵循以下数学定义:
| 类型 | 内存占用 | 取值范围 | 默认值 | 示例 | 适用场景 |
|---|---|---|---|---|---|
| byte | 1 字节 | -128 ~ 127 | 0 | byte b = 100; | 小范围数值(如文件字节流) |
| short | 2 字节 | -32,768 ~ 32,767 | 0 | short s = 200; | 历史遗留系统、低内存场景 |
| int | 4 字节 | -2³¹ ~ 2³¹-1 | 0 | int i = 1000; | 日常开发中的默认选择 |
| long | 8 字节 | -2⁶³ ~ 2⁶³-1 | 0L | long l = 1000L; | 超大数据 |
取值范围为什么是这些数字?
- 计算机用二进制存储数据,例如byte占8位二进制,最大表示0111 1111(十进制127),最小1000 0000(十进制-128)。
- 简单记忆:byte的范围 ≈ ±100 级别,int的范围 ≈ ±20 亿级别。
如何避免整数溢出?
- 当数值超出类型范围的时候,Java不会报错,而是“循环”到最小值。例如:
int max = 2147483647; // int 的最大值
int overflow = max + 1; // 结果变成 -2147483648(最小值)
TIP
这个现象的根本原因是Java使用补码来表示有符号整数。 补码的特性使得加减法无需区分正负数,统一使用加法运算。
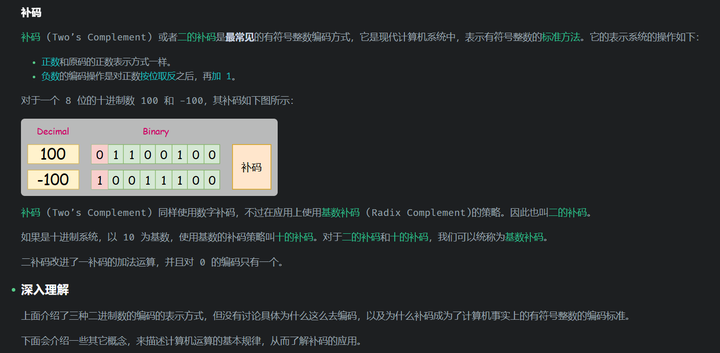
TIP
如果想要了解关于二进制、原码、反码、补码等计算机基础知识,可看下这个博客:二进制:有符号整数编码及加减法运算
- 使用更大范围的类型(如 long),或通过条件判断提前检查。
long类型必须加 L 后缀!
- 如果直接写long num = 100;,Java会默认100是int类型,可能导致溢出。
- long num = 100L;(相当于明确告诉编译器这是一个long类型的值)。
实践与建议
- 日常开发应该用哪种类型?
- 优先使用int:它在性能和内存占用之间平衡最好,绝大多数场景够用。
- 特殊场景:
- 处理文件、网络字节流 → byte
- 需要存储超大数字 → long
- 为什么short很少被使用?
- 现代计算机内存充足,short的优化意义不大,而且int的运算效率更高。
- 仅在历史遗留系统或特定硬件限制下需要用到short。
小练一下
byte b = 127;
b += 1;
System.out.println(b); // 输出什么?为什么?
2.2 浮点型
浮点型用于表示小数或科学计数法数值,Java提供了两种精度的浮点类型:float和double。它们是处理实数的核心工具,但也存在一些“反直觉”的特性需要特别注意。
| 类型 | 内存占用 | 精度范围 | 默认值 | 示例 | 适用场景 |
|---|---|---|---|---|---|
| float | 4 字节 | 约 ±3.4e38(6-7位有效数字) | 0.0f | float f = 3.14f; | 低精度需求(如简单图形计算) |
| double | 8 字节 | 约 ±1.7e308(15位有效数字) | 0.0d | double d = 3.14; | 日常开发默认选择(高精度场景) |
为什么浮点数会有精度问题?
- 计算机的二进制限制:浮点数基于IEEE 754标准,用二进制表示小数。许多十进制小数(如0.1)无法精确转换为二进制,导致舍入误差。
System.out.println(0.1 + 0.2); // 输出 0.30000000000000004(不等于 0.3)
double是默认类型
- 如果直接写3.14,Java会默认它是double类型。
- float必须加 f 后缀:
float f = 3.14; // 编译错误(3.14 默认是 double)
float f = 3.14f; // 正确(f和F都可以)
科学计数法表示
- 可以用 e 表示指数:
double d1 = 1.5e3; // 1500.0
double d2 = 2E-2; // 0.02
实践和建议
- 什么时候用float?什么时候用double?
- 优先使用double:精度更高,是Java推荐的默认浮点类型。
- 使用float的场景:
- 内存敏感(像大型数组)
- 低精度需求(像游戏中的坐标计算)
- 怎么精确计算小数(涉及到金融金额)
- 不用float,也不用double。
- 使用BigDecimal类(专门处理高精度小数)。
BigDecimal a = new BigDecimal("0.1");
BigDecimal b = new BigDecimal("0.2");
System.out.println(a.add(b)); // 精确输出 0.3
浮点型支持一些特殊值,需通过特定方法判断
| 特殊值 | 产生场景 | 判断方法 | 示例代码 |
|---|---|---|---|
| NaN | 0.0 / 0.0 | Double.isNaN(value) | System.out.println(0.0/0.0); // NaN |
| 正无穷大 | 1.0 / 0.0 | Double.isInfinite(value) | System.out.println(1.0/0.0); // Infinity |
| 负无穷大 | -1.0 / 0.0 | Double.isInfinite(value) | System.out.println(-1.0/0.0); // -Infinity |
小练一下
double a = 0.1;
double b = 0.2;
System.out.println(a + b == 0.3); // 输出什么?为什么?
2.3 字符型
字符型用于表示单个字符(如字母、数字、符号或特殊字符)。Java 的char类型基于Unicode编码,支持全球多种语言的字符。以下是它的核心特性和使用要点。
| 类型 | 内存占用 | 取值范围 | 默认值 | 示例 |
|---|---|---|---|---|
| char | 2 字节 | Unicode 字符(0 ~ 65535)Java SE 17 支持到 Unicode 13.0 | '\u0000' | char c = 'A'; |
Unicode编码和ASCII
- ASCII:早期编码标准,仅支持英文、数字和符号(0 ~ 127)。
- Unicode:全球统一编码标准,Java 的charchar使用UTF-16编码,可以表示65536 种字符(包括中文、日文、表情符号等)。
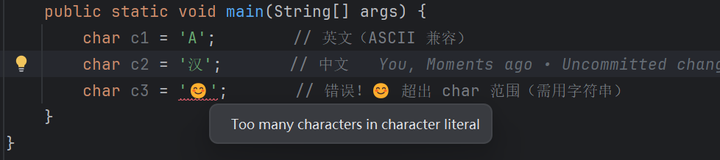
char c1 = 'A'; // 英文(ASCII 兼容)
char c2 = '汉'; // 中文
char c3 = '😊'; // 错误!😊 超出 char 范围(需用字符串)
用反斜杠 \ 表示特殊字符:
| 转义符 | 含义 | 示例代码 |
|---|---|---|
| \n | 换行 | System.out.print("Hello\nWorld"); |
| \t | 制表符(Tab) | System.out.print("Name\tAge"); |
| \ | 表示一个 \ | char c = '\'; |
| \uXXXX | Unicode 字符 | char c = '\u0041';(等价于 'A') |
字符与整数的关系
- char本质是无符号 16 位整数,可以直接参与数学运算:
char c = 'A';
int code = c; // code = 65(ASCII 值)
char next = (char)(c + 1); // 'B'
实践和建议
- char能存储中文字符吗?
可以,中文字符的Unicode编码在char的范围内(如 '汉' 的编码是 \u6C49)。
但某些复杂字符(如部分 emoji)需要两个char(代理对,Surrogate Pair)表示,这个时候就要用String了。
- char和String有什么区别?
char表示单个字符,String是多个字符组成的字符串。
char c = "A"; // char类型不能使用双引号,必须用单引号 'A'
- 为什么char占2字节?
这是为了支持Unicode(ASCII 只需要1字节)。UTF-16用2字节表示基础多语言平面(BMP)字符,超出范围的字符用代理对组合。
小练一下
怎么把一个字符从小写转为大写(如 'a' → 'A')?
2.4 布尔型
布尔型是 Java 中表示逻辑真/假值的类型,为条件判断设计。它只有两个取值:true和false,是控制程序流程(如if、while)的核心工具。
| 类型 | 内存占用 | 取值范围 | 默认值 | 示例 | 适用场景 |
|---|---|---|---|---|---|
| boolean | 无明确规范(JVM 实现相关) | true/false | false | boolean flag = true; | 条件判断、逻辑控制 |
布尔型的本质
- 严格逻辑隔离:Java的booleanboolean不能和整型(如int)互相转换,避免 C/C++ 中“非零即真”的歧义。
int num = 1;
if (num) { ... } // 编译错误!必须显式用布尔表达式
逻辑运算符
- 支持&&(逻辑与)、||(逻辑或)、!(逻辑非):
boolean a = true;
boolean b = false;
System.out.println(a && b); // 输出 false
- 短路求值
- &&和||会短路:如果左边表达式已能确定结果,右边就不会执行了。
if (false && (10 / 0 == 0)) { ... } // 不会抛出除以零异常(右边没执行)
实践和建议
- 为什么不用0和1代替布尔值?
Java强制使用true/false,避免因错误赋值(如误写if(x = 5))导致的逻辑漏洞。
明确的布尔值让条件判断更直观。
- boolean在 JVM 中如何存储?
单个boolean可能占1字节(Oracle JVM的实现)。
boolean数组可能压缩为1位(但实际以1字节存储)。
- 什么时候使用包装类Boolean?
集合存储,比如List<Boolean>必须用包装类。
自动拆箱时如果值为null,会抛出NullPointerExceptioNullPointerException异常
oolean flag = null;
if (flag) { ... } // 运行时抛出 NullPointerException
小练一下
boolean a = true;
boolean b = !a || (5 > 3);
System.out.println(b); // 输出结果?
编写一个判断闰年的逻辑表达式(闰年规则:能被4整除但不能被100整除,或能被400整除)。
三、Java 的类型转换与提升机制
在Java里,不同的基础数据类型之间可以相互转换。但为了类型安全,Java规定了明确的转换顺序和规则。
3.1 自动类型转换(隐式转换)
当数据从小范围类型转换成大范围类型时,Java会自动完成转换,不需要额外语法。
int i = 100;
long l = i; // OK
float f = l; // OK
自动转换顺序
byte → short → int → long → float → double
↘
char →
TIP
char虽然也是2字节,但由于是无符号类型,它不能自动转换为short,需要强制转换。
char c = 'A';
int code = c; // 自动转换
3.2 强制类型转换(显式转换)
当从大范围类型转换为小范围类型的时候,必须进行强制类型转换(显式 cast),不然就会出现编译报错。
double d = 3.14;
int i = (int) d; // 精度丢失,小数被截断 → i = 3
TIP
强制转换会有一定的风险:精度丢失或溢出
int x = 130;
byte b = (byte) x; // 溢出,b = -126
3.3 运算中的类型提升(计算规则)
在表达式里,较小的数据类型会被提升成较大的类型,以避免信息丢失。
- 所有byte、short、char会先提升为int参与计算:
byte a = 10;
byte b = 20;
byte c = (byte)(a + b); // a+b 提升为 int,需强转回 byte
- 如果表达式中有long、float、double,结果会向最大精度对齐:
int a = 1;
double b = 2.0;
System.out.println(a + b); // 结果为 double(a 被提升)
3.4 包装类型和自动拆装箱
Integer a = 100;
int b = a; // 自动拆箱:Integer → int
TIP
需要注意空指针的风险
Integer x = null;
int y = x; // 抛出 NullPointerException
3.5 小练一下
System.out.println(1 + 2.0); // 结果是什么类型?
System.out.println('A' + 1); // 会输出什么?
System.out.println("A" + 1); // 和上面有什么不同?
byte b = 1;
b = b + 1; // 编译错误?为什么?
float f = 1.0;
if (f == 1) { // 能不能通过编译?
...
}
TIP
在实际开发中,避免不同类型混合比较,尤其是 float/double 与 int 比较,优先使用BigDecimal或类型对齐判断。
四、基本类型 vs 引用类型的区别?
它们的内存布局、行为能力、语义特性都存在显著差异:
| 对比点 | 基本类型(primitive) | 引用类型(reference) |
|---|---|---|
| 存储内容 | 值本身(直接存储) | 引用(指针),指向对象 |
| 内存位置 | 栈内存中直接分配 | 堆内存中分配对象,栈上存引用 |
| 是否为对象 | 不是对象 | 是对象 |
| 是否支持方法 | 无方法 | 可调用对象方法 |
| 示例 | int x = 1; | Integer x = new Integer(1); |
int a = 100; // 存的是“值”
Integer b = new Integer(100); // 存的是“引用”
a的值直接保存在栈帧的局部变量表里。
b本质是一个指针,指向堆中那个Integer对象的地址。
所有引用类型的默认值为null,而基本类型有固定的默认值(如int为 0,boolean为 false)。
基本类型不能作为泛型的参数类型(需使用包装类,如List<Integer>)。
结语
今天,你已经系统地掌握了Java的8种基础数据类型:
- 占用空间、默认值、数值范围
- 类型转换规则、精度丢失、默认初始化
- 基本类型与引用类型的区别